우리는 항상 좀 더 나은 신경망, 좀 더 훈련이 잘된 인공지능 기법을 만들고자 한다.
그렇다면 신경망은 우리에게 보통 모든 노드들이 연결되어진 형태이다.
하지만 Dropout이라는 기술은 노드들을 꺼서 몇개의 노드들만 활성화된 상태로 훈련을 한다.
노드들을 끄는 확률은 조정할 수 있으며 몇개만 켜진 상태로 결과 값을 출력하게 한다. 이로써
조금 더 모든 노드들의 가중치가 최적화 될 수 있도록 만들 수 있다.
예를 들어 고양이인지 아닌지 판별하는 인공지능이 있다고 한다.
그랬을 때 판단하는 기준을 1번,2번,3번이라고 해보자.
1번 : 귀가 있는가
2번 : 눈이 있는가
3번 : 꼬리가 있는가
그리고 랜덤으로 1번,2번이 꺼진다고 해보자. 그리고 3번 노드만이 고양이인지 판별한다고 했을떄
이로써 조금더 최적화된 노드들을 가질 수 있게 된다.
이것이 바로 Dropout기술의 원리이다.
Essemble은 무엇인가?
Essemble은 데이터셋 별로 훈련을 따로 시킨다. 각각 가진 가중치들이 모두 다를 것이고 각 데이터마다 최적화된 노드들을 가질것이다. 그 모든 훈련된 것을 Combiner을 통해서 합쳐서 조금더 효율적으로 학습하는 것이다.
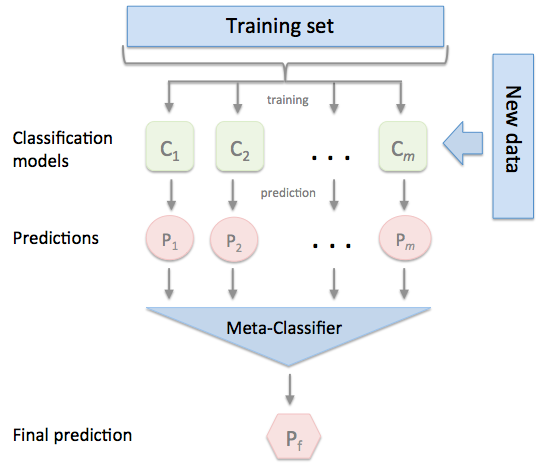
그리고 우리는 FeedFoward의 형태의 신경망을 학습하고 있다.
노드들이 앞으로 가면서 값을 얻어내는 형태이다. 우리는 Fast Foward, Split, Merge 와 같이 어떤 Net과 Net이 만나거나 나눠지거나 어떤 Net에서 나온 값이 조금 건너뛴 Net의 값으로 들어가는 형태도 만들 수 있다.
즉 FeedFoward는 우리의 창의력에서 조금 더 나은 , 조금 더 최적의 방법이 나올 수 있는 것이다.
나도 만들 수 있지 않을까 생각해본다! ㅎㅎ
'Artificial Intelligence' 카테고리의 다른 글
| CNN : Convolutional Neural Network (0) | 2019.11.02 |
|---|---|
| GAN : Generator와 Discriminator의 만남 (0) | 2019.11.01 |
| Backpropagation : XOR 문제를 해결한 기술 (0) | 2019.10.31 |
| Image Classification (0) | 2019.09.30 |
| XOR 문제를 해결하기 위한 딥러닝(딥넷트웍) (0) | 2019.08.29 |
